
مایکروسافت و TikTok به هوش مصنوعی مولد نوعی حافظه می دهند
به گزارش مجله هشت پیک مایکروسافت و TikTok به هوش مصنوعی مولد نوعی حافظه می دهند
که در این بخش به محتوای این خبر با شما کاربران گرامی خواهیم پرداخت
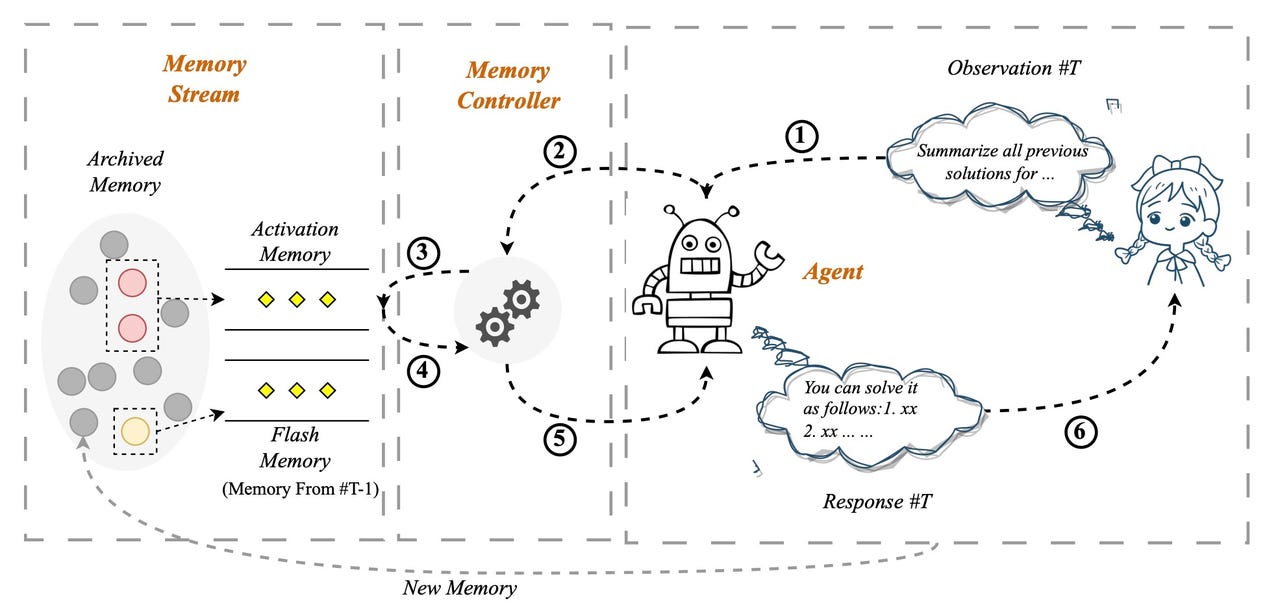
«سیستم حافظه خودکنترلشده» ByteDance، مالک TikTok، میتواند به بانک دادهای متشکل از صدها نوبت گفتگو و هزاران کاراکتر دسترسی داشته باشد تا به هر مدل زبانی قابلیتهایی برتر از ChatGPT بدهد تا به سؤالات مربوط به رویدادهای گذشته پاسخ دهد. ByteDance
وقتی چیزهایی را در دستور یک برنامه هوش مصنوعی مولد (AI) مانند ChatGPT تایپ می کنید، این برنامه نه تنها بر اساس آنچه تایپ کرده اید، بلکه بر اساس همه چیزهایی که قبلا تایپ کرده اید نیز به شما پاسخ می دهد.
شما می توانید آن تاریخچه چت را به عنوان نوعی خاطره در نظر بگیرید. اما به گفته محققان چندین مؤسسه، که تلاش میکنند هوش مصنوعی مولد را با چیزی شبیه به یک حافظه سازمانیافته که میتواند آنچه را تولید میکند تقویت کند، کافی نیست.
همچنین: نحوه استفاده از ChatGPT: همه چیزهایی که باید بدانید
مقاله ای که در این ماه توسط محقق Weizhi Wang از دانشگاه کالیفرنیا در سانتا باربارا و همکاران مایکروسافت با عنوان “افزایش مدل های زبانی با حافظه بلند مدت” منتشر شد و در سرور پیش از چاپ arXiv پست شد، مؤلفه جدیدی به زبان اضافه می کند. مدل ها.
مشکل ChatGPT است و برنامههای مشابه نمیتوانند متن کافی را در هر لحظه دریافت کنند تا زمینه بسیار طولانی برای چیزها داشته باشند.
همانطور که وانگ و تیم مشاهده می کنند، “محدودیت طول ورودی LLM های موجود مانع از تعمیم آنها به سناریوهای دنیای واقعی می شود که در آن توانایی پردازش اطلاعات طولانی فراتر از یک جلسه با اندازه ثابت بسیار مهم است.”
برای مثال، GPT-3 OpenAI حداکثر 2000 توکن، معنا، کاراکتر یا کلمه را دریافت می کند. شما نمی توانید مثلاً یک مقاله 5000 کلمه ای یا یک رمان 70000 کلمه ای برنامه را تغذیه کنید.
همچنین: این فناوری جدید می تواند GPT-4 و هر چیزی شبیه آن را منفجر کند
این امکان وجود دارد که “پنجره” ورودی را گسترش دهیم، اما با یک مشکل محاسباتی خاردار مواجه میشویم. عملیات توجه – ابزار ضروری همه برنامه های زبان بزرگ، از جمله ChatGPT و GPT-4 – دارای پیچیدگی محاسباتی “دوگانه” است (به “پیچیدگی زمانی” محاسبات مراجعه کنید). این پیچیدگی به این معنی است که مدت زمانی که ChatGPT برای تولید یک پاسخ طول میکشد، با مجذور مقدار دادهای که به عنوان ورودی تغذیه میشود، افزایش مییابد. افزایش بادکنک های پنجره ای مورد نیاز محاسبه می شود.
و بنابراین، برخی از محققان، وانگ و تیم، قبلاً سعی کردهاند خاطرهای خام را به دست آورند. یوهوای وو و همکارانش در گوگل سال گذشته چیزی را معرفی کردند که به آن ترانسفورماتور به خاطر سپردن میگویند، که نسخهای از پاسخهای قبلی را ذخیره میکند که در آینده میتواند از آن استفاده کند. این فرآیند به آن اجازه می دهد تا در یک زمان روی 65000 توکن کار کند.
اما وانگ و تیم متذکر می شوند که داده ها می توانند “کهنه” شوند. فرآیند آموزش ترانسفورماتور حافظه باعث میشود برخی چیزها در حافظه با بهروزرسانی وزنهای عصبی یا پارامترهای آن با شبکه عصبی هماهنگ نباشند.
راه حل وانگ و تیم، به نام “مدل های زبان تقویت شده با حافظه بلند مدت” یا LongMem، از یک مدل زبان سنتی بزرگ استفاده می کند که دو کار را انجام می دهد. همانطور که ورودی را بررسی می کند، مقداری از آن را در بانک حافظه ذخیره می کند. همچنین خروجی هر اعلان جریان را به یک شبکه عصبی دوم به نام SideNet ارسال می کند.
همچنین: چگونه ChatGPT را فریب دادم تا به من دروغ بگوید
SideNet که همچنین یک مدل زبان است، درست مانند شبکه اول، وظیفه دارد اعلان فعلی تایپ شده توسط یک شخص را با محتویات حافظه مقایسه کند تا ببیند آیا تطابق مرتبطی وجود دارد یا خیر. SideNet، بر خلاف Memory Transformer، می تواند به تنهایی جدا از مدل زبان اصلی آموزش داده شود. به این ترتیب، در انتخاب محتویات حافظه که کهنه نمیشوند، بهتر و بهتر میشود.
وانگ و تیم آزمایشهایی را برای مقایسه LongMem با Memorizing Transformer و با مدل زبان GPT-2 OpenAI انجام میدهند. آنها همچنین LongMem را با نتایج گزارش شده از ادبیات مدل های زبان دیگر، از جمله پارامتر 175 میلیاردی GPT-3 مقایسه می کنند.
آنها از وظایف مبتنی بر سه مجموعه داده استفاده می کنند که شامل خلاصه کردن متون بسیار طولانی، از جمله کل مقالات و کتاب های درسی است: پروژه گوتنبرگ، سرور فایل arXiv و ChapterBreak.
برای ارائه ایده ای از مقیاس این وظایف، ChapterBreak، که سال گذشته توسط Simeng Sun و همکارانش در دانشگاه ماساچوست Amherst معرفی شد، کتاب های کامل را می گیرد و یک مدل زبان را آزمایش می کند تا ببیند آیا با توجه به یک فصل به عنوان ورودی، می تواند به دقت از چند قسمت نامزد مشخص کنید که کدام یک شروع فصل بعدی است. چنین کاری «نیازمند درک غنی از وابستگیهای دوربرد» است، مانند تغییرات مکان و زمان رویدادها، و تکنیکهایی از جمله «آنالپسیس»، که در آن، «فصل بعدی یک «فلاش بک» به نقطه قبلی روایت است. ”
همچنین: به گفته یک متخصص هوش مصنوعی، هوش مصنوعی بیشتر از تغییرات آب و هوایی باعث نابودی جهان می شود
و شامل پردازش ده ها یا حتی صدها هزار توکن است.
زمانی که Sun و تیم آن تستهای ChapterBreak را اجرا کردند، سال گذشته گزارش دادند که مدلهای زبان غالب “مبارزه” داشتند. به عنوان مثال، GPT-3 بزرگ تنها در 28 درصد مواقع درست بود.
اما برنامه LongMem “به طرز شگفت انگیزی” همه مدل های زبان استاندارد را شکست داد، وانگ و تیم گزارش دادند، از جمله GPT-3، با ارائه یک امتیاز پیشرفته 40.5٪، علیرغم این واقعیت که LongMem تنها حدود 600 میلیون پارامتر عصبی دارد. ، بسیار کمتر از 175 میلیارد GPT-3.
وانگ و تیمش می نویسند: «پیشرفت های اساسی در این مجموعه داده ها نشان می دهد که LONGMEM می تواند زمینه طولانی گذشته را در حافظه پنهان درک کند تا مدل سازی زبان را به سمت ورودی های آینده به خوبی تکمیل کند.
کار مایکروسافت بازتاب تحقیقات اخیر در ByteDance، مادر اپلیکیشن رسانههای اجتماعی TikTok است.
محقق Xinnian Liang از ByteDance و همکارانش در مقاله ای که در آوریل در arXiv با عنوان “بازسازی ظرفیت ورودی بی نهایت طول برای مدل های زبانی در مقیاس بزرگ با سیستم حافظه خودکنترل شده” منتشر شد، یک برنامه الحاقی ایجاد کردند که هر مدل زبانی بزرگی را ارائه می دهد. توانایی ذخیره توالی های بسیار طولانی از موارد صحبت شده.
همچنین: مدیر ارشد فناوری MongoDB میگوید هوش مصنوعی توسعه نرمافزار را به روشهای گسترده تغییر خواهد داد
آنها ادعا می کنند که در عمل، این برنامه می تواند به طور چشمگیری توانایی یک برنامه را برای قرار دادن هر درخواست جدید در متن و در نتیجه بیان عبارات مناسب در پاسخ – حتی بهتر از ChatGPT، بهبود بخشد.
در «سیستم حافظه خودکنترلشده» که به آن SCM گفته میشود، ورودیهایی که کاربر در اعلان تایپ میکند توسط یک کنترلکننده حافظه ارزیابی میشود تا ببیند آیا نیاز به فرو رفتن در یک سیستم حافظه بایگانی به نام جریان حافظه دارد یا خیر. تعاملات گذشته بین کاربر و برنامه بیشتر شبیه SideNet و بانک حافظه همراه وانگ و تیم است.
در صورت نیاز به حافظه، مجموعه ورودی گذشته از طریق ابزار پایگاه داده برداری مانند Pinecone قابل دسترسی است. ورودی کاربر یک پرس و جو است و برای ارتباط با آنچه در پایگاه داده است مطابقت دارد.
برخی از درخواستهای کاربر به حافظه نیاز ندارند، مانند “Tell me a joke” که یک درخواست تصادفی است که هر مدل زبانی میتواند از عهده آن برآید. اما یک پیام کاربر مانند “آیا نتیجه ای که هفته گذشته در مورد رژیم های تناسب اندام گرفتیم را به خاطر دارید؟” چیزی است که نیاز به دسترسی به مطالب چت گذشته دارد.
در یک پیچ و تاب دقیق، درخواست کاربر و حافظه ای که بازیابی می کند، در چیزی که مقاله آن را “تلفیقی ورودی” می نامد با هم ترکیب می شوند – و این متن ترکیبی است که به ورودی واقعی مدل زبان تبدیل می شود که بر اساس آن پاسخ خود را ایجاد می کند. .
همچنین: این سیستم هوش مصنوعی جدید می تواند حدود نیمی از زمان ذهن ها را با دقت بخواند
نتیجه نهایی این است که SCM می تواند ChatGPT را در وظایفی که شامل ارجاع به صدها نوبت قبل در دیالوگ است، بالاتر ببرد، لیانگ و تیم را بنویسید. آنها SCM خود را به نسخه ای از GPT-3 به نام text-davinci-003 متصل کردند و نحوه عملکرد آن را با ورودی یکسان در مقایسه با ChatGPT آزمایش کردند.
در یک سری بیش از 100 نوبت، شامل 4000 توکن، زمانی که انسان از دستگاه میخواهد سرگرمیهای فرد مورد بحث در ابتدای جلسه را به خاطر بیاورد، «سیستم SCM پاسخ دقیقی به سؤال ارائه میکند و حافظه استثنایی را نشان میدهد. آنها می نویسند – قابلیت های افزایش یافته، در حالی که، در مقابل، به نظر می رسد که ChatGPT توسط مقدار قابل توجهی از داده های تاریخی نامربوط منحرف شده است.
این کار همچنین می تواند هزاران کلمه از متن های طولانی مانند گزارش را خلاصه کند. این کار را با خلاصه کردن مکرر متن انجام می دهد، که به معنای ذخیره اولین خلاصه در جریان حافظه و سپس ایجاد خلاصه بعدی در ترکیب با خلاصه قبلی و غیره است.
SCM همچنین میتواند باعث شود که مدلهای زبان بزرگ که رباتهای چت نیستند، مانند رباتهای چت رفتار کنند. آنها می نویسند: “نتایج تجربی نشان می دهد که سیستم SCM ما LLM ها را که برای گفتگوی چند دور بهینه سازی نشده اند، قادر می سازد تا به قابلیت های گفتگوی چند نوبتی که با ChatGPT قابل مقایسه است دست یابند.”
هر دو کار مایکروسافت و TikTok را می توان به عنوان توسعه دهنده قصد اصلی مدل های زبان در نظر گرفت. قبل از ChatGPT و سلف آن، Google's Transformer، وظایف زبان طبیعی اغلب توسط شبکههای عصبی مکرر یا RNN انجام میشد. شبکه عصبی بازگشتی نوعی الگوریتم است که می تواند به داده های ورودی قبلی برگردد تا آن را با ورودی فعلی مقایسه کند.
همچنین: GPT-4: ظرفیتی جدید برای ارائه توصیه های غیرقانونی و نمایش “رفتارهای اضطراری خطرناک”
ترانسفورماتور و LLM مانند ChatGPT جایگزین RNN ها با رویکرد ساده تر – توجه شدند. توجه به طور خودکار هر چیزی را که تایپ شده است با هر چیزی که قبلا تایپ شده مقایسه می کند، به طوری که گذشته همیشه در بازی آورده می شود.
بنابراین، کار تحقیقاتی مایکروسافت و TikTok به سادگی توجه را با الگوریتم هایی گسترش می دهد که به صراحت برای یادآوری عناصر گذشته به شیوه ای سازمان یافته تر ساخته شده اند.
افزودن حافظه چنان تنظیم اساسی است که احتمالاً در آینده به یک جنبه استاندارد از مدلهای زبان بزرگ تبدیل میشود، و این امر باعث میشود که برنامهها بتوانند به مطالب گذشته، مانند تاریخچه چت، ارتباط برقرار کنند، یا به مسائل مربوطه بپردازند، بسیار متداولتر میشود. متن کامل آثار بسیار طولانی
امیدواریم از این مقاله مجله هشت پیک نیز استفاده لازم را کرده باشید و در صورت تمایل آنرا با دوستان خود به اشتراک بگذارید و با امتیاز از قسمت پایین و درج نظرات باعث دلگرمی مجموعه مجله 8pic باشید
لینک کوتاه مقاله : https://5ia.ir/Fep
کوتاه کننده لینک
کد QR :

















آخرین دیدگاهها